+-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | 0 N/A N/A 19968 C+G ...ge\Application\msedge.exe N/A | | 0 N/A N/A 21008 C ...64\Debug\CudaRuntime1.exe N/A | +-----------------------------------------------------------------------------+
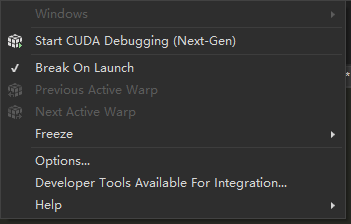
但是根据资料查到,原生调试时程序并不会运行于GPU而是CPU之上,需要借助插件才能实现GPU运行,但是我这里不需要使用插件即可运行于GPU之上,但是为了严谨,这里贴出插件的位置。位于工具栏->扩展->Nsight,需要打开Break On Launch才能进行调试。